サイトをまるごとダウンロードする方法(wgetコマンド編)

サイトをローカルにダウンロードする方法(wgetコマンド編)
コマンドラインからサイトをまるごとダウンロードする方法です。
使用するコマンド:wget
意外と知られていませんが、UNIX系OS(Ubuntu, CentOS、Linux)にはサイトをまるごとダウンロード出来るwgetコマンドが用意されています。
今回はwgetコマンドを使った簡単な実例と、実用的なオプションをご紹介します。
前準備(wgetコマンドの存在を確認)
コマンドラインから以下を実行してみて下さい。
$ wget -V
バージョン情報が表示されたらコマンドは準備済みです。
例:$ GNU Wget 1.19.4 built on darwin17.3.0.
もし
$ command not found
と表示されたらコマンドがインストールされていません。
以下のコマンドでインストールを行いましょう。
|
1 2 3 4 5 |
Ubuntu, CentOSの場合 $ sudo yum install wget mac(OSX)の場合 $ brew install wget |
はじめてのwget
wgetコマンドは、HTTPアクセスをしてコンテンツをファイルに保存するコマンドです。
再帰的にたくさんのファイルをダウンロードすることができるのでバックアップにも便利です。
実践:yahooのトップ画面をダウンロードしてみよう
Yahooのトップページをダウンロードして見ましょう。
コマンドは以下です。
$ wget yahoo.co.jp
|
1 |
wget yahoo.co.jp |
実践:実行結果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[hogehoge]:local-wget-yahoo:$ wget yahoo.co.jp --2018-11-05 22:12:46-- http://yahoo.co.jp/ yahoo.co.jp (yahoo.co.jp) をDNSに問いあわせています... 182.22.59.229, 183.79.135.206 yahoo.co.jp (yahoo.co.jp)|182.22.59.229|:80 に接続しています... 接続しました。 HTTP による接続要求を送信しました、応答を待っています... 301 Moved Permanently 場所: https://www.yahoo.co.jp/ [続く] --2018-11-05 22:12:46-- https://www.yahoo.co.jp/ www.yahoo.co.jp (www.yahoo.co.jp) をDNSに問いあわせています... 182.22.28.252 www.yahoo.co.jp (www.yahoo.co.jp)|182.22.28.252|:443 に接続しています... 接続しました。 HTTP による接続要求を送信しました、応答を待っています... 200 OK 長さ: 特定できません [text/html] `index.html' に保存中 index.html [ <=> ] 18.32K --.-KB/s 時間 0.05s 2018-11-05 22:12:46 (380 KB/s) - `index.html' へ保存終了 [18756] |
あっさりとヤフーのトップページがindex.htmlファイルとして実行フォルダに取得、保存できました。
ブラウザに無理矢理表示してみましょう。
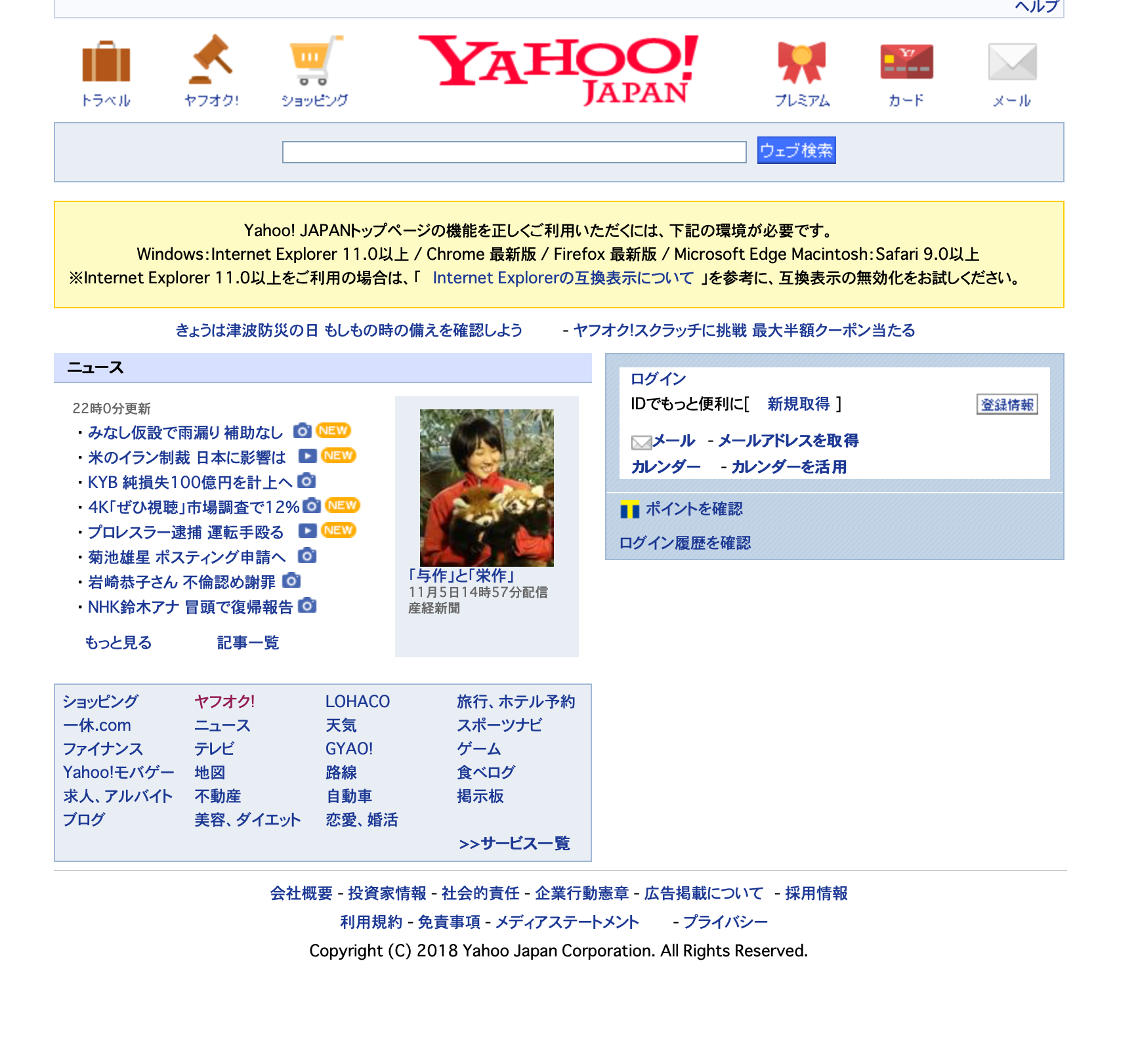
無事ダウンロード出来ましたね。
ところで、本家のYahooトップページと比べると画像やリンクなど全体の情報が少ないですね。
この点は深く今回は説明いたしませんが、サイトにアクセスしたエージェント(OSやブラウザなど)がwgetコマンドだったため、と頭の片隅に置いておいて下さい。iPhoneでYahooにアクセスしたらTOP画面がPCとは異なりますよね?それと似たようなことが起こっています。
wgetコマンドオプション
wgetは強力なオプションを備えています。
上手に活用する事で、欲しいサイトの情報を効率的にダウンロードする事が出来ます。
以下に私がオススメする代表的なオプションをご紹介します。
wgetの秘めたる力を引き出すオプションたち
| -r | 再帰的なダウンロードを実行。ドメイン名のディレクトリを作成してダウンロードしたファイルを保存する |
| -l数字 | リンクをたどる最大回数を指定。-l1 は指定したURLとそのリンク先をダウンロード。-r も合わせて必要 |
| -w数字 | ダウンロードの間隔を秒数で指定 |
| -p | そのHTMLページに含まれる画像やCSS、JavaScriptなどもダウンロードする。 その1ページだけでよければ、-r を付けなくてもよい |
| -k | リンクや画像への参照などを、ローカルでも開けるように絶対パスから相対パスに書き換える |
| -A 拡張子 | ダウンロードするファイルの拡張子を指定。コンマ区切りで複数指定できる。 再帰的にリンクをたどるためにHTMLにもアクセスをするがファイルで保存するのは指定の拡張子のみになる。 例: -A jpg,png,gif |
オプションを指定した実践例
サイトが参照されている画像ファイルやその他ファイル(css、jsなど)もまとめてダウンロードする方法
ウェブページのHTMLと参照されている画像ファイルやCSS、JSなどもまとめてダウンロードするには
オプション -p を使います。参照されている画像やCSSやJSも合わせてまるごとダウンロードしてくれます。
$ wget -p http://www.hogehoge.com/
サイトを丸ごとダウンロードする方法
サイトのリンクを自動的にたどって、リンク先もどんどんダウンロードするには
オプション -r を指定します。また、リンクをたどる深さ(深度)を オプション -l で指定します。
深度がわからないサイトを無限にダウンロードするのは無謀ですし、サイト管理者、閲覧者に迷惑が掛かります。
深度の指定は必ず行うことと、無理の無い設定を心がけて下さい。
以下はリンク3回までたどり、ダウンロードする。
リンクを3回踏むということは第4階層のページまでダウンロードする事になります。
$ wget -r -l3 http://www.hogehoge.com/
ダウンロード時のモラル
サイトのダウンロードには大きな負荷がかかります。
サイト運営者や閲覧者にご迷惑が掛からないよう以下のオプションは絶対に付けて下さい。
絶対につけよう! -w オプション!!!
-w オプションは、再帰的なダウンロードの途中一度一度にインターバルを設けるオプションです。
-w1 は一秒、-w2 は2秒のインターバルを設けてダウンロードされます。
模範的コマンド実行例
$ wget -r -l3 -w2 http://www.hogehoge.com/
ダウンロード速度は遅くなりますが、回線もサーバリソースもみんなの共有物です。
是非譲り合いの精神で素敵なwgetライフをお送り下さい。
最後までご覧頂きありがとうございました。
特定サイトに集中的にアクセスすると不正アクセスとみなされ、アカウントロックやIP遮断、場合により営業妨害などで訴訟を起こされる可能性もあります。アカウントロックやIP遮断でも復活はおそらく望めません。細心の注意のもと行って下さい。

関連記事





コメント
この記事へのトラックバックはありません。



この記事へのコメントはありません。